These days a lot of folks in the SEO world are focused on “user intent” and satisfying the queries that people are using to find what they’re after. They look at everything from user profiles and implicit user feedback (bounce rate, time on site, dwell time etc) to entities and more. But one thing I really don’t seem to see a lot of is how Google is actually handling the queries.
Over the last few years people have gravitated to RankBrain, BERT and more. Beyond that if we go back further, we tend to look at concepts over keywords since Google went to “things not strings”. But something I really don’t see a lot of is; query classifications.
Google and Query Classification
Today we’re going to look at a few patents/papers to see what might be at play with Google and hopefully teach you a few things to help further your thinking when performing this “thing of ours”. To better understand what it is, be sure to read my 2014 article over here.
In the patent “Query Classification” (granted in 2015) Google states
“Queries are classified as belonging to a particular category based on search result filtering settings for that particular category. The classification can thus be done independent of the content of the query, and therefore queries with ambiguous or emergent terms that cannot be classified by machine learned systems can still be accurately classified.”
And uh.. lol?
“The classifications can be used, for example, to adjust relevance scores to adjust a position of a search result in a ranking of search results for unfiltered search operations. For example, if the query is not categorized as a content type seeking query (e.g., not categorized as a pornography seeking query), and the query is received for an unfiltered search operation, then the search engine decreases a relevance score for each resource that includes content of that content type (e.g., resources that include pornography).”
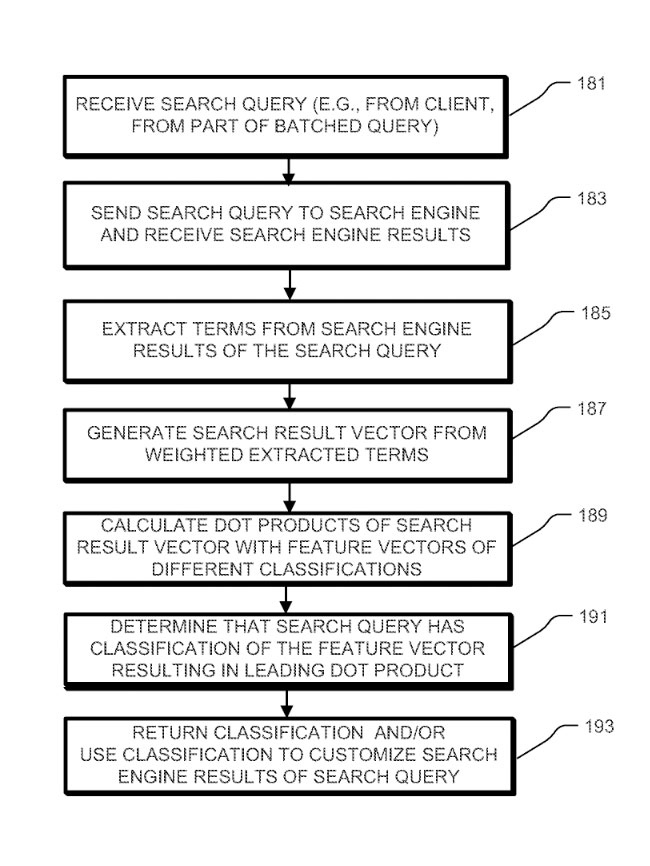
Anyway, you get the idea. Obviously topically they can classify things as well.. as noted in the 2014 patent; “QUERY CLASSIFICATION BASED ON SEARCHENGINE RESULTS”
“In one embodiment, the predetermined classifications rep resent topics, for example movie, music, sports, business, politics, and books. In another embodiment, the predetermined classifications represent corpuses, for example a col lection of general web, news, question and answer, image, and video data. In yet another embodiment, the predetermined classifications reflect topics and corpuses.”
And an example they give is;
“For instance, for the movie classification, example queries can be “inception”, “the lord of the rings movie’, and “how to train your dragon’’. The example queries of “inception”, “the lord of the rings movie’, and “how to train your dragon” in turn generate search engine results with terms for the movie classification. These terms specific to the movie classification can be signals indicative of a movie classification.”
And we can also understand some classification elements in the more traditional, “informational”, “transactional” and “navigational” queries. But that’s evolved so much more since the early days when we all used to talk about that approach. In fact, some of the earliest mentions of vectors in Google patents/papers, come from query classification methods.
Possible classification approaches
There’s a myriad of methods to classifying queries and this can be inclusive of;
- Past queries for the user
- Query refinements in the session
- Entity correlations
- Collections of queries from multiple users
- Identifying contextual intent (e.g. use of pronoun or other referential term in the query)
- Query re-write – Replacing a term with a synonym
These kinds of approaches can be used when a search engine essentially re-writes a query to better deliver relative results. This can be seen in the 2017 Google patent, “Query rewriting using session information”
In which they state;
“For example, the use of a pronoun in the current search query can indicate that the pronoun can be replaced by a particular entity. Entities can be identified in the prior search queries and substituted into the current search query as candidate rewrites. For example, if the current received search query is [how old is he], the pronoun “he” indicates that the object is a person entity. If one of the prior search queries is [Barack Obama], the entity can be substituted to generate candidate rewrite [how old is Barack Obama]. Similarly, if the current received search query is [where is it] natural language analysis suggests that the “it” refers to a place or thing entity. Thus, if one of the prior search queries is [Golden Gate Bridge year built], the entity can be substituted to generate the candidate rewrite [where is Golden Gate Bridge].”
So in the above example, we see some of what Google calls “conversational” search. As such, we can intimate that Google doesn’t just return results based on the actual query, but also uses a myriad of methods to re-write and/or better understand not only the current query, but past queries (from the user, multiple users or the session itself) to try to better understand what the actual need of the user is from the given query at the time.
In fact your page might satisfy queries that you may not have even be targeting.
“(…) generating a refined search query having one or more terms from the one or more entity text strings for the first document, including combining (i) one or more terms of the one or more entity text strings for the first document with (ii) one or more terms of the first search query; and providing the refined search query having the one or more terms from the one or more entity text strings for the first document in response to receiving the first search query.”
This really does make one think outside the box as far as how users are even finding your content. As with all things search, it’s never as simple as it seems.
Beyond keywords
All of this starts to teach us that we’re not really living in a world of matching keywords to queries. Traditional keyword research (and associated tools) really just don’t help give you what you might need, content wise, to satisfy a given query. Sure, it’s a good starting point for potential volume, but that’s about it
And for content development be sure to keep related terms and entities in mind as noted in one of the patents we’ve looked at today;
“(…) the search engine can receive a search query “Mona Lisa” from the client. The search engine can identify search results that are responsive to the search query “Mona Lisa”. The search results can identify documents that are relevant to the search query. Entities including “Leonardo da Vinci”, “Louvre”, “renaissance”, and other character strings associated with the Mona Lisa can be associated with the documents by the search engine 140 and provided to the refinement server.”
And hey, it probably never hurts to look at things like Google Suggest, People Also Ask or Related Searches. These are also likely part of Google’s data for query re-writing and classifications.
Outside the box
These days with all the chatter we’ve seen over various “buzz-words” such as RankBrain, Hummingbird, BERT and more… which is fine. But so many folks don’t even consider the basics of information retrieval. And modern approaches to query classification and re-writing have evolved. You can see elements of vectors, entities and more. It’s never to late to look back to the basics.
We can also infer that “rankings” aren’t all they’re cracked up to be either. Google’s query classification and query re-writing approaches can mean that what the user types in and what’s returned, can be drastically different things at times.
As always with me.. this is just an article to get the thoughts flowing. I encourage you to research more and learn.
Until next time…. Stay frosty.
More Reading;
Great stuff, David! As I’ve been ranting for a couple of years now, “rankings” are no longer just a moving target – they’re essentially meaningless, as Google interprets both content and query on-the-fly, with so many variables that the whole process is fluid. Nice job clarifying some of the things that contribute to that.
Thanks brother… and yea, as we were talking about the other day, folks seem to not get that query classifications can really move the goal-posts as far as what “rankings” are and what content they might need to drive Google traffic.